
Fixing EKS DNS
Getting rid of EKS DNS issues at scale
Reading time: about 12 minutes
I got to blog on the AWS Containers Blog: EKS DNS at scale and spikeiness! 🎉
I usually just get to mentor people, and they get to post stuff publicly, so this is a nice change!
NoteThe AWS Containers Blog now seems to be missing my blog post, so here's a copy:
WarningThis post is somewhat outdated!
The ideas presented here are still valid, but NodeLocal DNS evolved and changed. Some of the information presented here was merged into the upstream documentation.
For the latest information, check out the official docs!
EKS DNS at scale and spikeiness
This is a guest post by Vlad Ionescu for Ownzones.
In his post we will discuss the issue of DNS errors at scale, that is, several hundreds to thousands of nodes, showing how the problems can be mitigated. This was an obstacle that affected Ownzones for several months and a problem that we expect everybody at scale will encounter. Two solutions will be proposed and their implementation will be discussed. Troubleshooting steps are shared for easy identification of the problem.
Ownzones is a pioneering technological force that’s transforming the OTT industry with ground-breaking innovations. Our product Ownzones Connect is a cloud-native platform, which leverages our proprietary technology as well as the best tools in the industry to provide studios an agile, low-cost solution for global distribution and localization. Some of the key features include the world’s first fully cloud-based, parallel processing IMF transcoder.
Problem
At Ownzones, we run our applications in containers for increased developer velocity. Due to rather intense scaling requirements — a multi-TB movie comes in and needs to be processed as soon as possible — the decision was made to use Kubernetes for container orchestration. Since we are running in AWS, we make use of the amazing Amazon Elastic Kubernetes Service or EKS for short. We leverage other AWS services such as Amazon Relational Database Service, Amazon ElastiCache, and more. We manage all the services and infrastructure configuration in code with Terraform and we practice gitops with Atlantis.
The EKS clusters are running version 1.12 and we are in the process of upgrading all our clusters to 1.13. Each cluster has a different configuration depending on the customer needs for scale, but all of them scale a lot. As soon as jobs come in — be they transcoding jobs, media analysis jobs, deliveries, or anything else — the EKS clusters are scaled up by cluster-autoscaler. At peak, clusters may scale to hundreds or thousands of nodes to process the work as soon as possible.
The problems started to appear when customers or internal testing teams were scaling the system to higher limits, such as when transcoding or using FrameDNA to analyze large films or libraries of content. When the Kubernetes cluster was doing intense work and scaling above several hundreds of nodes, the processing time was stagnating or increasing. Having built a cloud native solution, the expectation was that adding additional processing power would lower the processing time.
We quickly established a cross-functional task force to investigate this issue.
A multitude of tools are used for observability at Ownzones: Honeycomb for events and traces, Sysdig for monitoring, Papertrail for logs, Sentry for error tracking, and more. Investigation into traces from Honeycomb showcased DNS resolution times taking seconds or more:

In some cases DNS lookups were taking multiple seconds:

Looking further into network metrics showed DNS errors spiking while work was being processed and recovering when the work was finished:
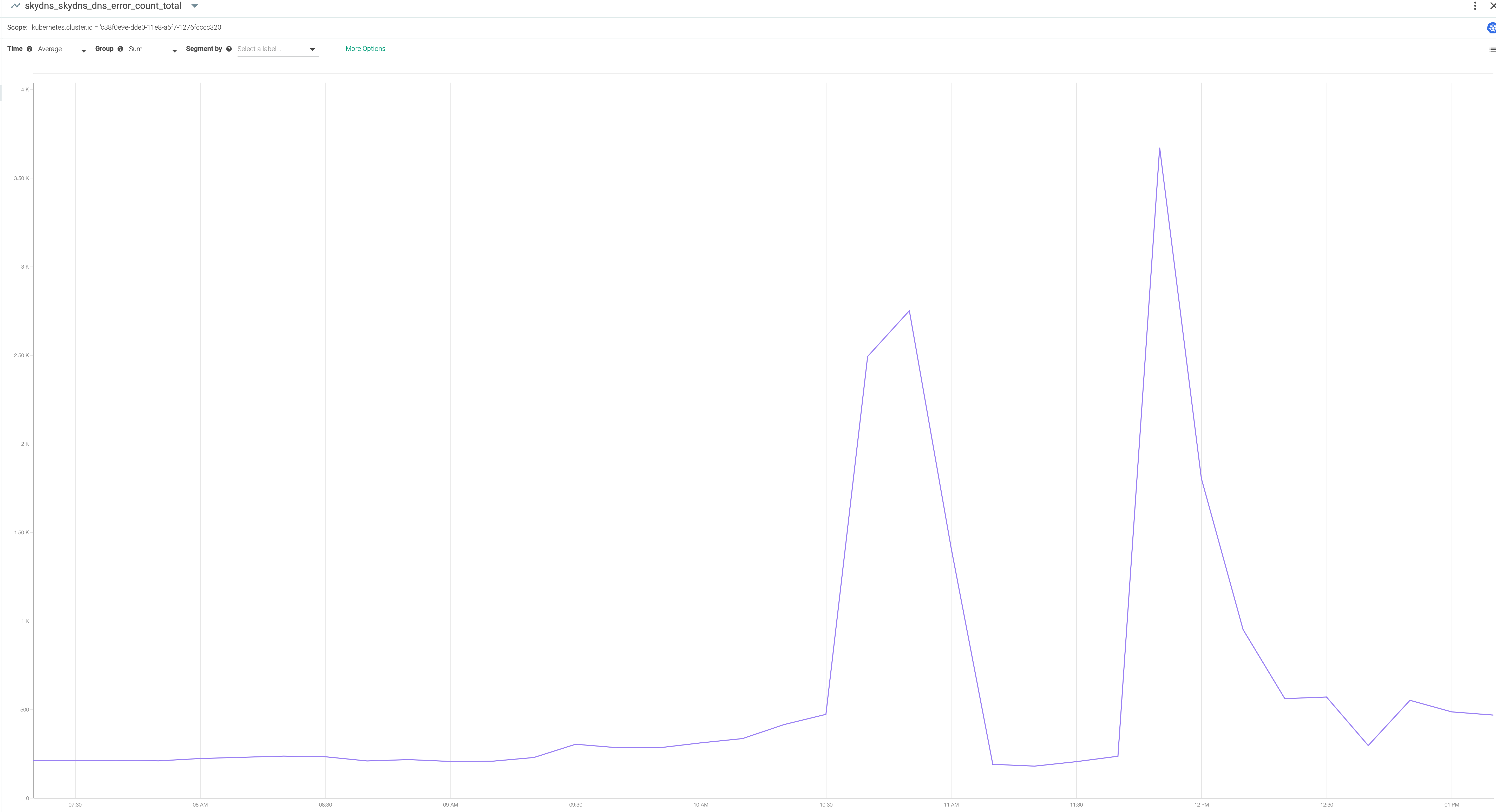
The culprit was identified: when reaching a certain scale, a significant number of DNS errors (EAI_AGAIN and ENOTFOUND) that were leading to a lot of retries. Operations that were supposed to take a couple minutes were taking orders or magnitude longer. For example, transcoding a single 4K feature film in Ownzones Connect takes around 16 minutes. During this time, the EKS cluster is scaled to hundreds of nodes, which are peaking at 1.64 TB/s network traffic to S3 and 8.55k requests per second to S3. And that is for a single video track! Processing files in massively parallel ways is where cloud native approaches shine and Ownzones Connect is fully taking advantage of that. The result is a massive spike of work and DNS traffic. Having multi-second lookup times when doing 8.550 requests per second to S3 adds up to quite a lot.
Since the cause was narrowed down to DNS, the next step was to contact AWS Support. The DNS issues were appearing at scale and spiky workloads were especially affected. After investigation by AWS it was confirmed that the VPC networking was not experiencing elevated error rates, nor was S3. It was pointed out that due to the Amazon VPC DNS Limits of 1024 packets per second per network interface the EKS-default 2 CoreDNS pods can be quickly overloaded. Each CoreDNS pod has to serve DNS traffic from the host through its own elastic network interface, which is limited to 1024 packets per second.
Attempt one: increasing CoreDNS pods
The first and easiest improvement for DNS failures was to increase the number of CoreDNS pods. By default EKS has two replicas and that can be increased:
kubectl scale deployment/coredns \
--namespace kube-system \
--current-replicas=2 \
--replicas=10
At Ownzones, we run both on On-Demand Instances as well as on Spot Instances. This is not ideal as CoreDNS pods could be scheduled on a Spot Instance, which may be terminated at any time and potentially add disruption.
To work around this we edited the CoreDNS deployment to only run on On-Demand EC2 instances which we have tagged with the stable label:
kubectl --namespace kube-system edit deployment/coredns
...
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/os
operator: In
values:
- linux
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
- key: nodegroup
operator: In
values:
- stable
containers:
...
Scaling the CoreDNS pods was an improvement, but we still saw significant error rates. We had thousands of nodes sending network traffic to 10 CoreDNS pods, which were spread on significantly fewer On-Demand nodes.
WarningThis post is somewhat outdated!
The ideas presented here are still valid, but NodeLocal DNS evolved and changed. Some of the information presented here was merged into the upstream documentation.
For the latest information, check out the official docs!
Attempt two: Node-local DNS
Kubernetes developers have an addon that addresses the DNS problem: NodeLocal DNS Cache. Using this addon, a new CoreDNS DaemonSet can be configured so it runs on each node. Those new CoreDNS pods will act as a DNS cache: all pods on a specific node would have their requests sent to the local CoreDNS pod which would either serve a result from cache or forward the request upstream to the main CoreDNS pods.
This massively lowers the volume of DNS queries and makes spike handling a breeze and follows the AWS recommendation to cache DNS. The first step is to decide which IP will be used for NodeLocal DNS. Typically 169.254.20.10 is chosen.
With the IP address decided, the YAML files from k/k/cluster/addons/dns/nodelocaldns need to be acquired. They cannot be applied directly as some values need to be replaced:
__PILLAR__DNS__DOMAIN__withcluster.localas per amazon-eks-ami’s kubelet-config.json.__PILLAR__LOCAL__DNS__with169.254.20.10, which is like the default address chosen above that the Node-local DNS will bind to on each node.__PILLAR__DNS__SERVER__with10.100.0.10or172.20.0.10depending on the VPC CIDR. On EKS, the DNS Service is running at one of the two IPs and the relevant one needs to be chosen. The value can be seen by runningkubectl -n kube-system get service kube-dnsand checking the cluster IP.
After the values are replaced the files have to be applied:
kubectl apply -f nodelocaldns.yaml
This is not enough: Node-local DNS was installed, but it is not used by the pods! To actually have the pods use Node-local DNS the kubelet running on each node needs to be configured. The DNS resolver for the pods needs to point to the newly created Node-local DNS server running at 169.254.20.10 on each node.
Users of the amazing eksctl project can easily configure this since support was added in February by editing the node group definition:
...
nodeGroups:
- name: mygroup
clusterDNS: 169.254.20.10
...
Users of the Terraform community EKS module have to send an extra parameter to the kubelet binary in the worker group definition:
...
worker_groups_launch_template = [
{
...
name = "mygroup";
kubelet_extra_args = "--node-labels=kubernetes.io/lifecycle=spot,nodegroup=mygroup --cluster-dns=169.254.20.10";
...
},
{
...
},
]
...
That’s all!
At Ownzones, we have been running the above setup in production for more than 2 months on Amazon EKS and Kubernetes 1.12 with very good results. DNS errors have fallen drastically with 99% of DNS queries resolved in less than 2ms during stress-testing:
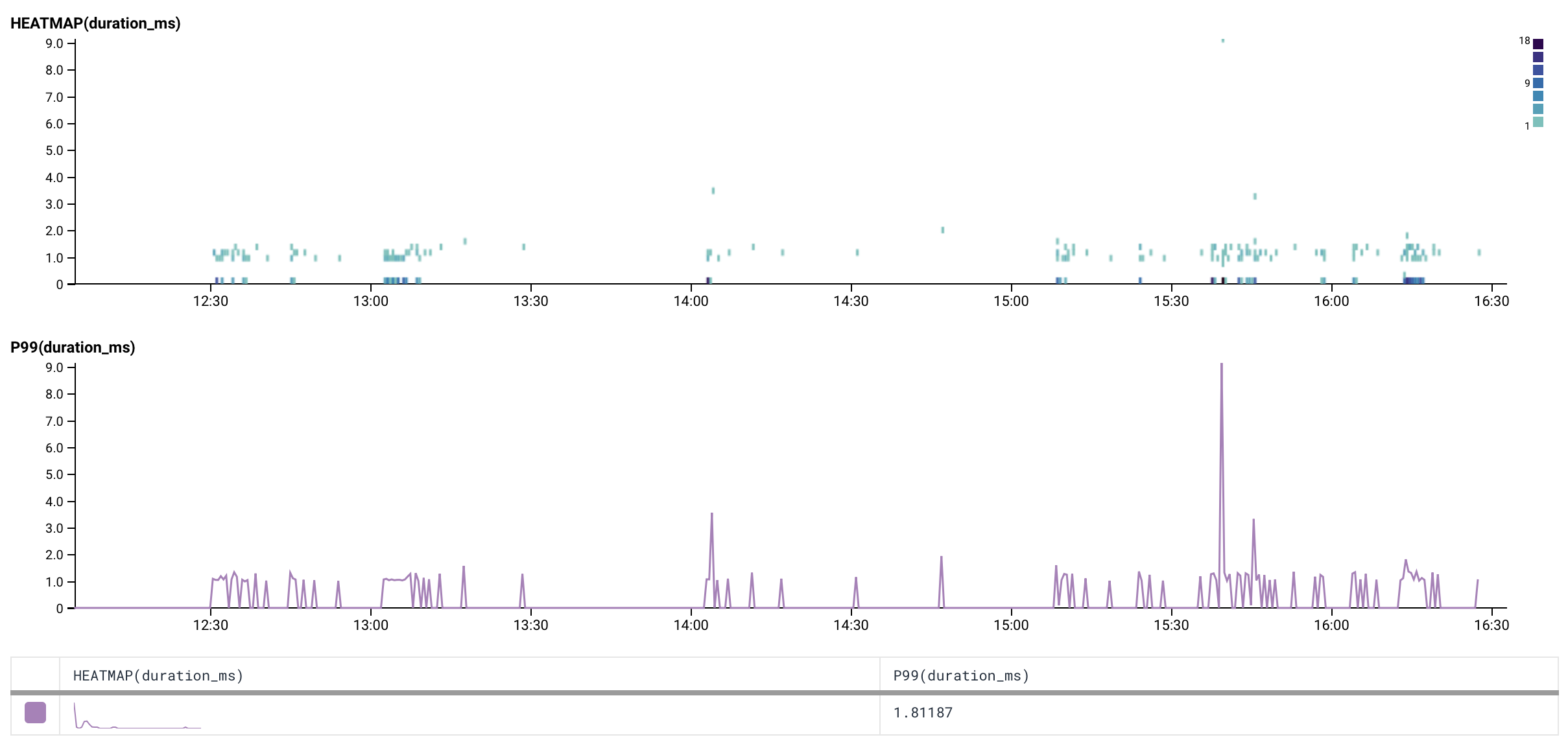
Troubleshooting tips
Identifying the need for a more in-depth DNS configuration is not straightforward. Debugging Node-local DNS is a task in itself that requires networking experience and familiarity with networking in Kubernetes.
To lower the time investment, we can share two pointers that would have helped us a lot when starting the investigation.
Visibility
Knowing how many CoreDNS replicas to use and knowing if NodeLocal DNS is needed are both two very hard questions. Prometheus and Grafana can showcase the relevant metrics on the CoreDNS dashboard.
While at Ownzones we debugged resolution issues with Honeycomb, a tracing solution combined with a rich monitoring setup will likely reach the same depth. An important point is for the investigation to happen in-depth with attention paid to outliers and spikes. The P99 for DNS resolution may be low, but all DNS lookups at peak could take seconds.
WarningThis post is somewhat outdated!
The ideas presented here are still valid, but NodeLocal DNS evolved and changed. Some of the information presented here was merged into the upstream documentation.
For the latest information, check out the official docs!
Debugging Node-local DNS
Netshoot is described as a Docker + Kubernetes network trouble-shooting swiss-army container and fully lives up to the promise. It can be used to debug DNS resolution issues and it can be used to check if NodeLocal DNS is actively being used.
To confirm that NodeLocal DNS is bounded to the right address, a pod using the host network can be started:
kubectl run tmp-shell-host --generator=run-pod/v1 \
--rm -it \
--overrides='{"spec": {"hostNetwork": true}}' \
--image nicolaka/netshoot -- /bin/bash
Running netstat -lntp in the pod should show the 169.254.20.10 address bound on 53 port, which is used for DNS:
netstat -lntp
...
tcp 0 0 169.254.20.10:53 0.0.0.0:* LISTEN -
...
To confirm that applications running on Kubernetes are actually resolving DNS through NodeLocal DNS cache, a pod using the default network can be started:
kubectl run tmp-shell-no-host-net --generator=run-pod/v1 \
--rm -it \
--image nicolaka/netshoot -- /bin/bash
Running dig example.com in the pod should show the 169.254.20.10 address as the server responding to the DNS query:
dig example.com
...
;; Query time: 2 msec
;; SERVER: 169.254.20.10#53(169.254.20.10)
;; WHEN: Wed Sep 25 12:58:42 UTC 2019
;; MSG SIZE rcvd: 56
...
Running in a pod on a node where Node-local DNS is badly configured or not present will show the cluster DNS service being used (10.100.0.10 or 172.20.0.10 depending on the VPC CIDR):
dig example.com
...
;; Query time: 3 msec
;; SERVER: 172.20.0.10#53(172.20.0.10)
;; WHEN: Tue Oct 08 08:13:48 UTC 2019
;; MSG SIZE rcvd: 56
...
Future plans
The current solution with NodeLocal DNS is stable and is working consistently, but further improvements can be done.
Having a single CoreDNS pod on each node also means having a very critical single point of failure. Currently there is no NodeLocal DNS support for high availability, but that should not be that big of a concern for cloud native applications. NodeLocal DNS limits the issues to a single node and if NodeLocal DNS needs to restart or is having issues only that specific node is being affected. While NodeLocal benefits from liveness probes and restarting handled by Kubernetes, node-problem-detector could be used for more comprehensive failure handling and is something that is worth researching.
WarningThis post is somewhat outdated!
The ideas presented here are still valid, but NodeLocal DNS evolved and changed. Some of the information presented here was merged into the upstream documentation.
For the latest information, check out the official docs!